How to set up LLM analytics for ChatGPT
Apr 05, 2024

Tracking your ChatGPT API usage, costs, and latency is crucial to understanding how your users are interacting with your AI and LLM powered features. In this tutorial, we show you how to monitor important metrics such as:
- Total cost
- Average cost per user
- Average API response time
We'll build a basic React app, implement the ChatGPT API, and capture these events using PostHog.
1. Create a React app
To showcase how to track important metrics, we create a simple one-page React app with the following:
- A form with textfield and button for user input.
- A label to show ChatGPT output.
- A dropdown to select different OpenAI models.
First, ensure Node.js is installed (version 18.0 or newer). Then run the following script to create a new React app and install both the OpenAI JavaScript and PostHog Web SDKs:
Next, we set up Posthog using our API key and host (You can find these in your project settings). Replace the code in src/index.js with the following:
Lastly, replace the code in App.js with our basic layout and functionality. You can find your Open AI API key here.
Run npm start to see our app action:
2. Capture chat completion events
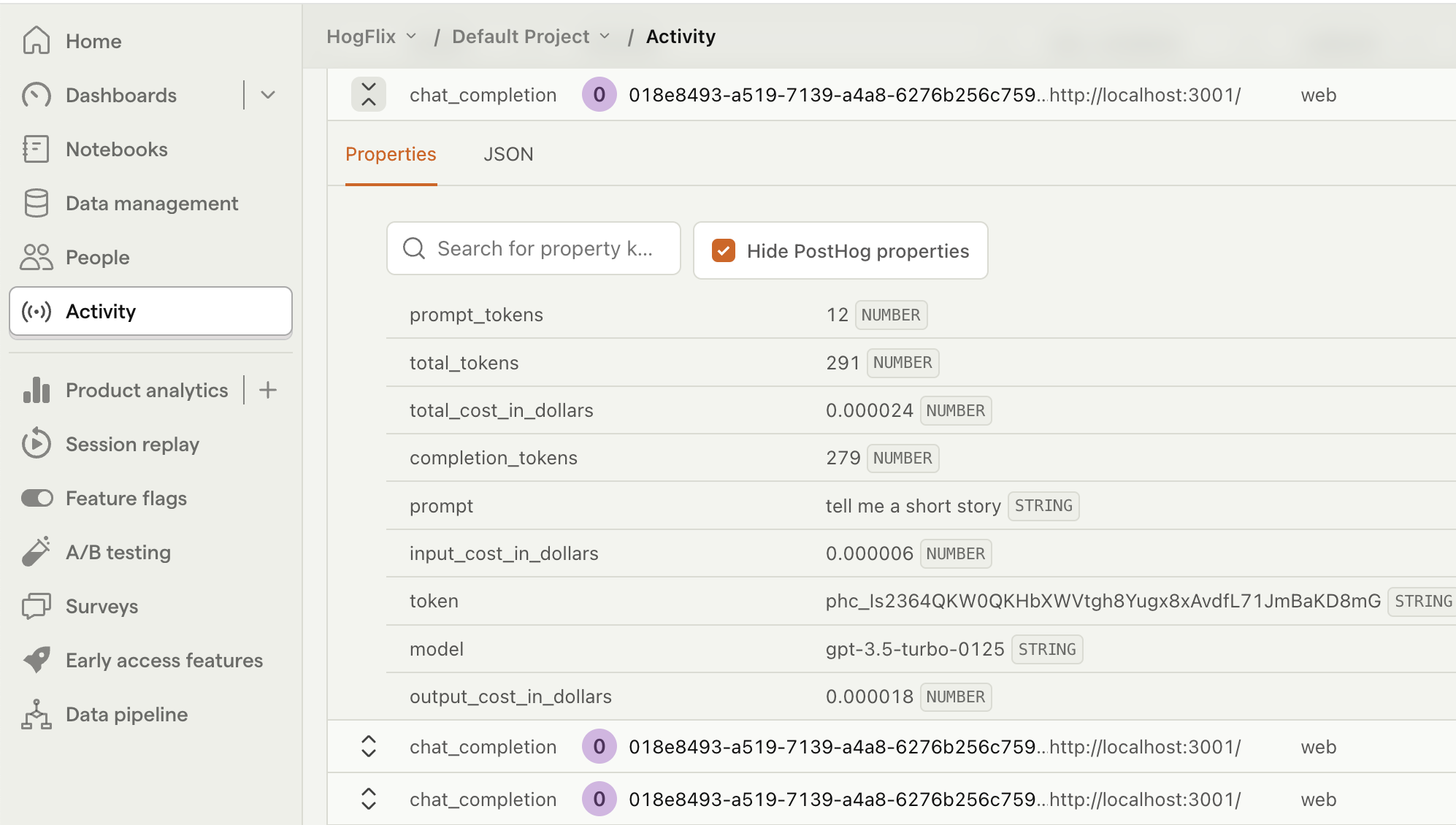
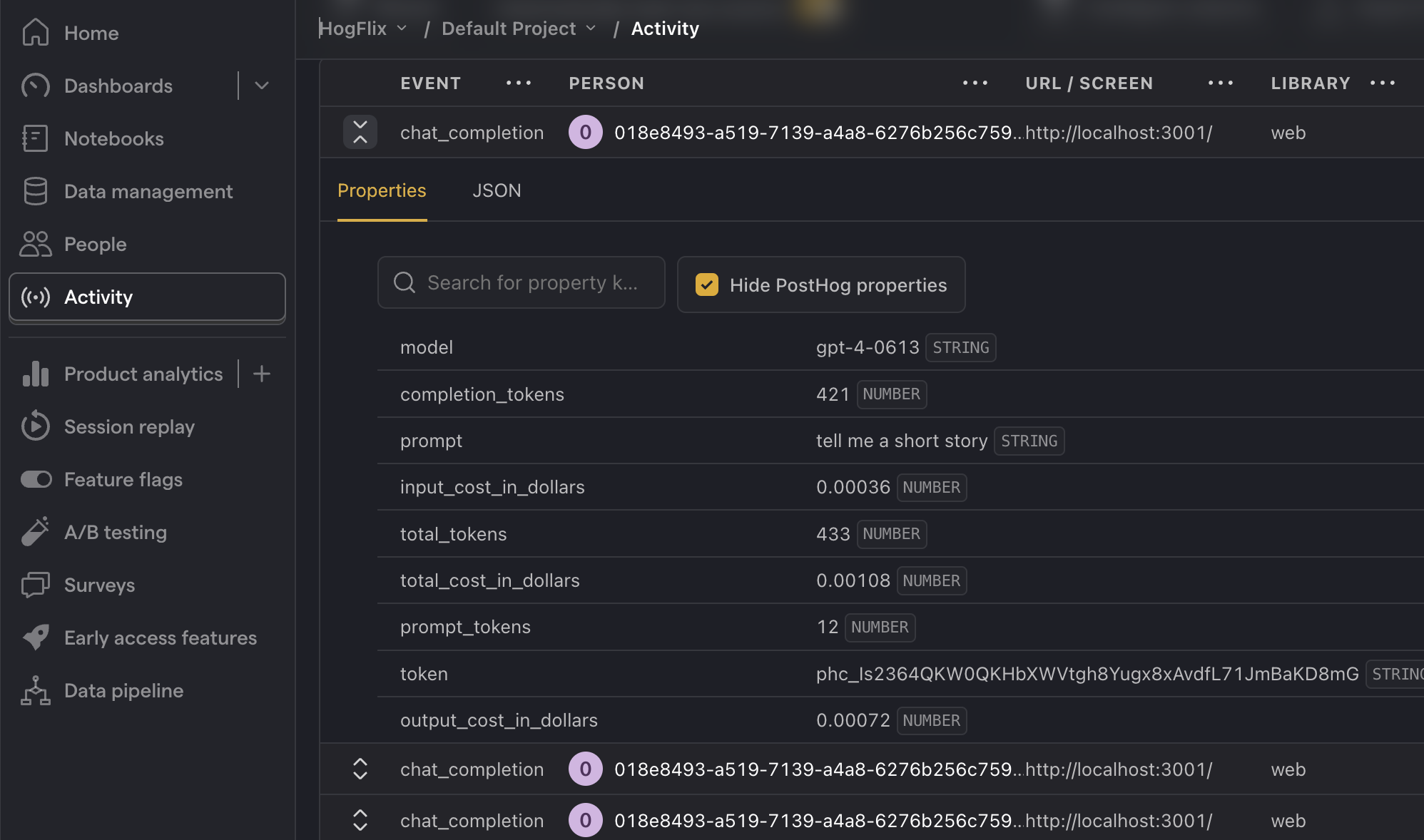
With our app set up, we can begin capturing events with PostHog. To start, we capture a chat_completion event with properties related to the API request. We find the following properties useful to capture:
promptmodelprompt_tokenscompletion_tokenstotal_tokensinput_cost_in_dollarsi.e.prompt_tokens*token_input_costoutput_cost_in_dollarsi.e.completion_tokens*token_input_costtotal_cost_in_dollarsi.e.input_cost_in_dollars + output_cost_in_dollars
Update your fetchChatGPTResponse() function in App.js to capture this event:
Refresh your app and submit a few prompts. You should then see your events captured in the PostHog activity tab.
3. Create insights
Now that we're capturing events, we can create insights. Below are three examples of useful metrics you should monitor:
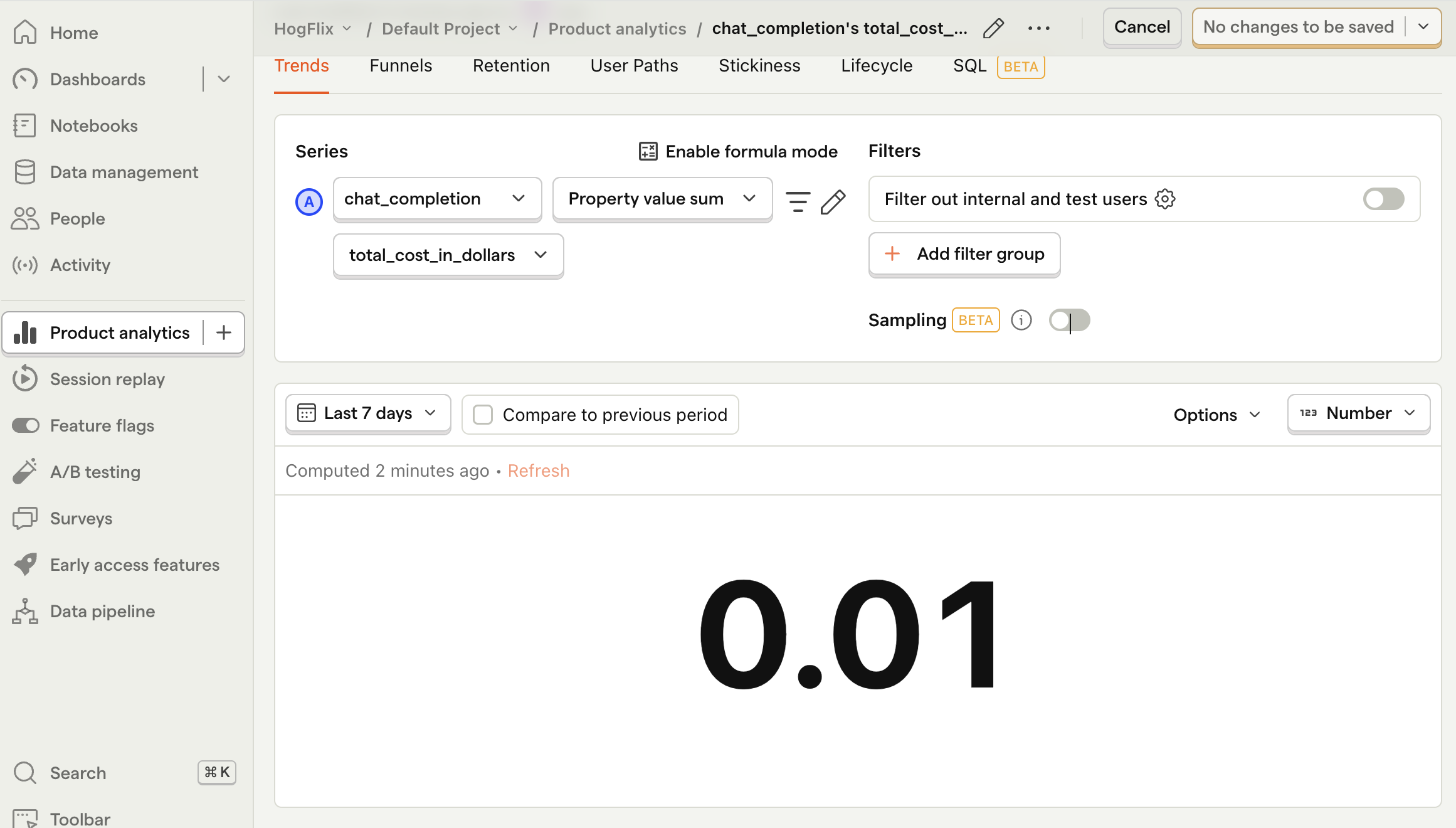
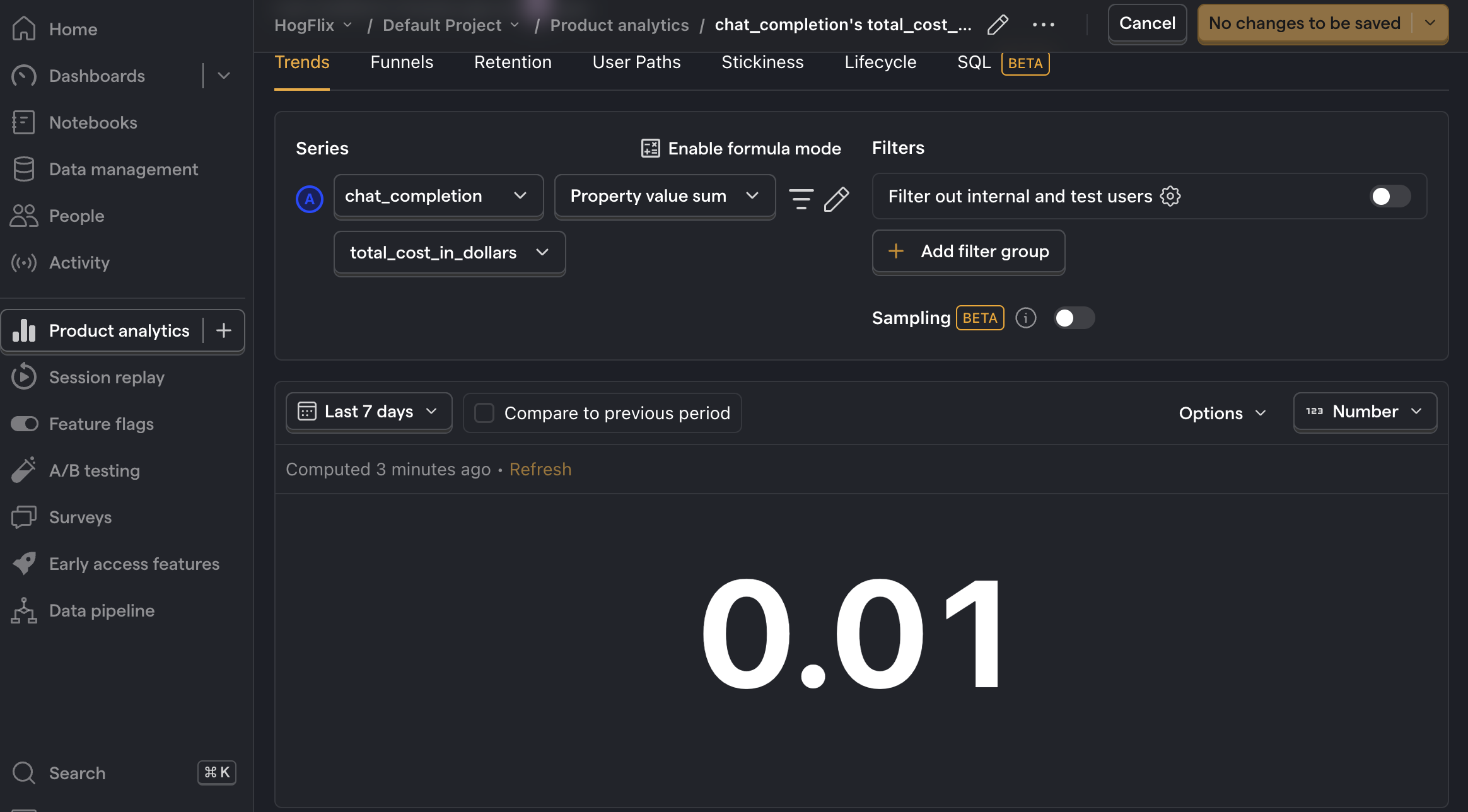
Total cost
To create this insight, go the Product analytics tab and click + New insight. Then:
- Set the event to
chat_completion - Click on Total count to show a dropdown. Click on Property value (sum).
- Select the
total_cost_in_dollarsproperty.
Then, change the chart type from Line chart to Number (or however else you'd like to visualize your data). Note that it may show 0 if your total cost is smaller than 0.01.
Additionally, you can also breakdown your costs by model. To do this, click + Add breakdown and select model from the event properties list.
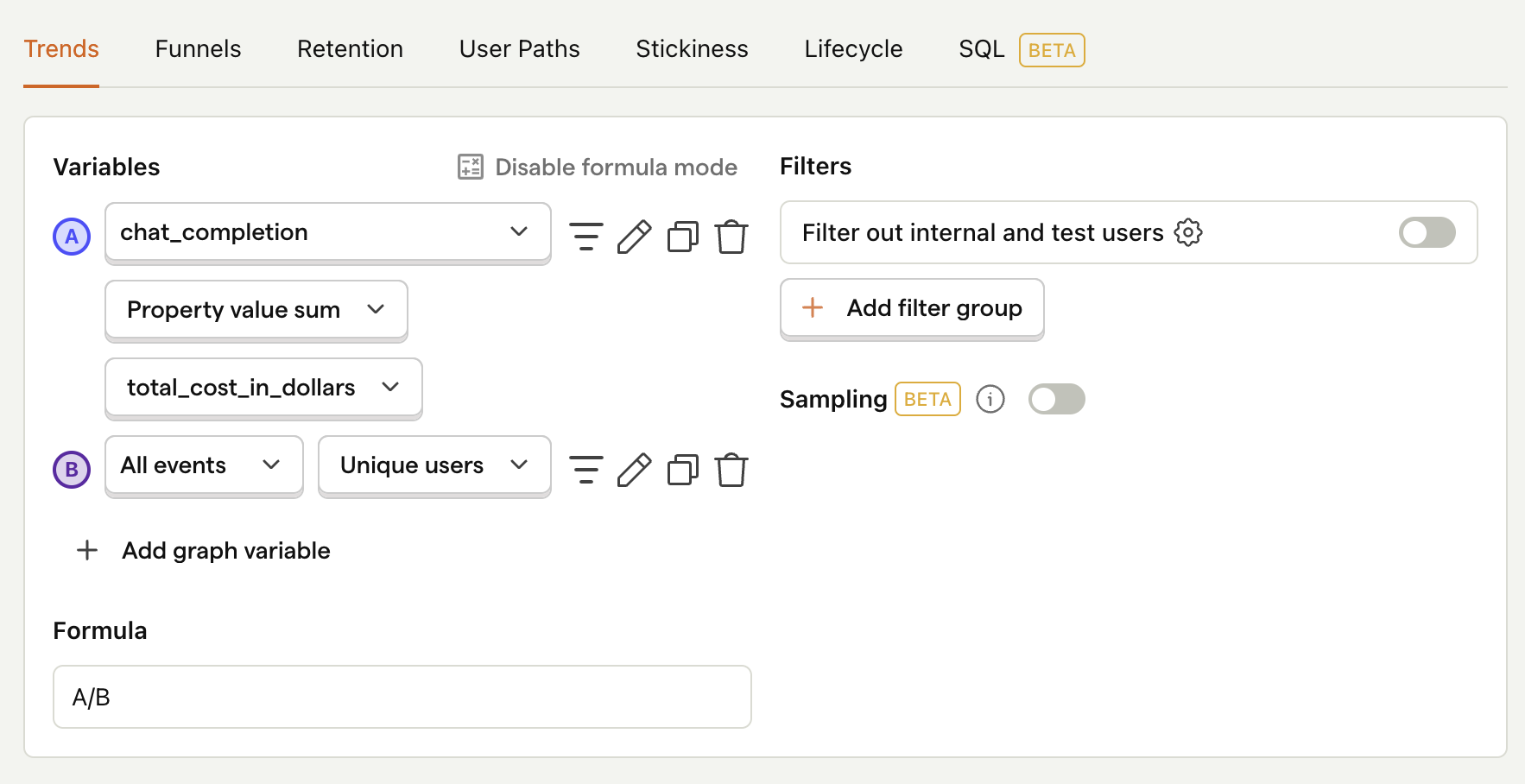
Average cost per user
This metric helps give you an idea of how your costs will scale as your product grows. Creating this insight is similar to creating the one above, however we use formula mode to divide the total cost by the total number of users:
- Set the event to
chat_completion - Click on Total count to show a dropdown. Click on Property value (sum).
- Select the
total_cost_in_dollarsproperty. - Click + Add graph series (if your visual is set to
number, switch it back totrendfirst). - Keep the event name as
All events, but change the value fromTotal counttoUnique users. - Click Enable formula mode.
- In the formula box, enter
A/B.
Once again, note that it may show 0 if the number is smaller than 0.01.
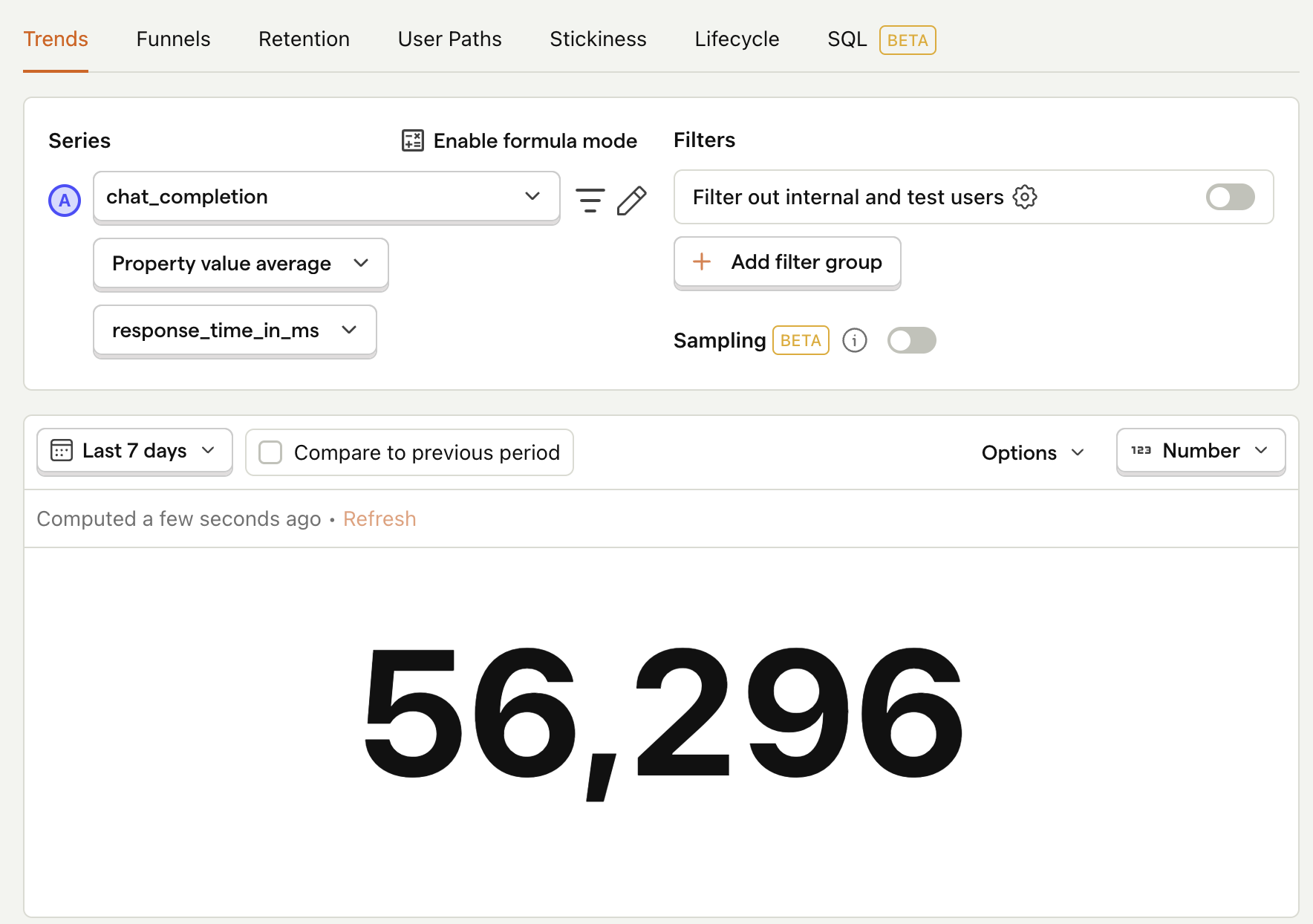
Average API response time
ChatGPT's API response time can take long, especially for longer outputs, so it's useful to keep an eye on this. To do this, first we need to modify our event capturing to also include the response time:
Then, after capturing a few events, create a new insight to calculate the average response time:
- Set the event to
chat_completion - Click on Total count to show a dropdown. Click on Property value (average).
- Select the
response_time_in_msproperty.
Next steps
We've shown you the basics of creating insights from your product's ChatGPT API usage. Below are more examples of product questions you may want to investigate:
- How many of my users are interacting with my LLM features?
- Are there generation latency spikes?
- Does interacting with LLM features correlate with other metrics e.g. retention, usage, or revenue?
Further reading
- Product metrics to track for LLM apps
- How to set up LLM analytics for Anthropic's Claude
- How to set up LLM analytics for Cohere